神译局是找邦企头条旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:当你点开Netflix为你推荐的新剧时,你也许不知道,这部剧配的海报是专门为你挑选的。几年来,Netflix一直致力于研发它的用户个性化推荐系统,简单来说就是根据用户留下的数据、经过复杂的算法框架,最终配上最可能吸引用户点开链接的海报。那么,这种算法框架具体是如何运行的呢?它的优势又在哪里?作者在文中为读者解答。本文来自Medium,作者Ashok Chandrashekar, Fernando Amat, Justin Basilico和Tony Jebara,原文标题“Artwork Personalization at Netflix”.
推荐阅读:
给用户配个性化海报:Netflix的算法让你忍不住点开推荐(上)

Netflix已经成为越来越多人追剧的主流平台|图片来自Unsplash|摄影CardMapr
Contextual bandits算法框架
Netflix的推荐系统是靠机器学习而不断升级的。我们会收集用户的相关数据,然后放到算法中不断更新算法系统。
但是具体选用哪一种算法呢?传统的方法是进行A/BTest,这种离线的检测方法是说,我们将用户分成A和B两组,我们对A组用户保持老算法,对B组用户使用新算法,然后看效果:如果新的算法效果更好,我们就会全面切换成新的算法,反之则保留旧的算法。
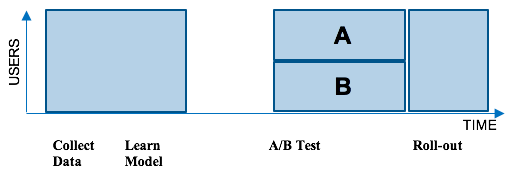
但问题在于,每个组的用户活跃度是不一样的,因此测试的结果不一定准确。假设B组的成员更加活跃,测试得到的结果是新算法更好,我们就对所有用户全部采用新算法。但是新算法不一定适用于每个用户,因此就会造成新算法让某些用户无法获得更好体验的结果,即示意图中的绿色部分“Regret”。

为了最大程度地减少Regret用户的数量,我们开始采用在线机器学习法。以前的机器学习需要收集数据、让算法更新、进行A/BTest然后再比较算法优劣,这个过程很长,而且效果并不好。现在我们采用Contextual bandits算法框架,在这个框架下,模型可以快速辨识出用户的喜好并作出推荐。
这个算法框架是什么?
Contextual bandits算法框架是一款在线的算法框架,可以在线收集训练数据、实时学习、迅速反馈,为每位用户生成无偏差模型,而且可以立即生效。
在早期的工作中,我们用算法框架在没有具体场景的情况下挑选出最优图片。现在我们需要个性化的推荐,所以就把用户当成不同的“场景”(context),根据他们对图片不同的需要和反馈进行调整,
Contextual bandits算法框架的核心目标是缩短上图中Regret用户的数量。这一框架可以通过注入随机的、用于训练算法的数据,从而得到一般性的公式,即使环境千变万化也能迅速适应。我们把这个过程称之为“数据探索”。数据探索的具体策略和剧集提供的图片、用户的数量(也称之为数据的规模)相挂钩。
在这种数据探索的过程中,我们还会记下信息日志,这些日志可以用来训练实时模型,也可以在离线测试时作出更加准确的效果评估,这个一会儿我们会更详细地说明。
当然,数据探索都是有成本的,因为在探索的过程中,总会有一部分用于测试的用户没能享受最终的、最优的体验。这样做的结果是什么呢?
事实上,在拥有1亿多用户的情况下,这一部分没能享受最优化体验的人数(或者每位用户无法享受最优化体验的时间)是非常少的,所以分摊下来的话,这种数据探索的成本并不大,这种代价也是完全可以接受的。
如果根据结果,这种随机数据探索的代价太大了的话,Contextual bandits算法框架就不适用了。
我们现在推行的在线数据探索方案帮我们建立了一个数据库,数据库里每个小组中都有用户数量和数据、剧集、图像等。我们根据算法提供的结果决定要不要给某位用户提供每个剧集的推荐。
此外,这种数据探索是可控的,我们可以根据用户的反馈进行调整,保证用户在同一个剧集链接中看到的图片变化的频率是有限的。除此之外,我们还尽量仔细地标注数据的质量,以免出现“钓鱼图”(吸引用户点击但是没有什么内容的图片,类似“标题党”),引发负面反馈。
模型训练
在线上学习的设定中,我们用Contextual bandits算法框架为基础,根据每位用户的需求和倾向问他们呈现不同的海报。对每一个用户来说,我们一般都有12张左右的海报备选。
但是每位用户看每个剧集时都有12张图像备选,我们又有这么多用户和剧集,所以可想而知,挑选的工作量是巨大的。
为了简化这种训练,我们不再为每位用户排列某个单独的剧集的海报,而是对一个用户会接触到的所有剧集的海报进行整体排列。按照后者的排列方法,我们依旧可以针对某一个剧集找到最适合用户的海报。具体的学习方法我们采用监督学习法(supervised learning models)、汤普森采样法(Thompson Sampling)、LinUCB或贝叶斯推断法(Bayesian methods ),这些方法可以帮助我们在数据探索中作出最佳决策。
潜在的信号
在Contextual bandits算法框架中,不同的场景通常有明显的特征,可以借助这些特征来辨识不同的场景。这些特征也可以称之为“信号”。用户在使用Netflix的过程中会呈现很多特征/信号,比如他们点击过的标题、他们选择的国家,或者他们的语言偏好设置,他们登陆Netflix的设备,他们看剧的时间和周期,等等。我们的算法在为用户进行个性化推荐的同时,也会将上述的信号考虑在内。

用户在Netflix看剧的同时,Netflix也在分析用户的各类特征,形成“用户画像”|图片来自Unsplash|摄影Clay Banks
有一件事是需要慎重考虑的:有的时候,同一个剧集的某些海报质量和效果天生就比另一些海报要高。在我们数据探索的过程中,也会给这些海报打分。在以前非个性化的海报推荐中,我们会把评分最高的海报无差别地呈现给所有用户,现在有了算法,我们根据用户需求把可能最吸引他们的海报呈现给他们。
在这个过程中,我们要考虑如何在“最高质量”和“最适合用户”的海报之间做选择,这时候信号就显得很重要了。如果一位用户发出的信号越强烈,那么我们就给他推荐最适合他的(但可能不是质量最高的)海报;反之,我们则更倾向于为他推荐质量最高的海报。
图片选择
正如前文所言,图像选择就是给不同的用户、按照他们的喜好为他们呈现特别定制的海报。一旦前文中提到的模型训练完成,我们就可以将它立马投入使用,用来检测某位用户看某部剧时如果看到候选的几张海报,分别有多大的概率会点开它。我们根据这样的概率从高到低排顺序,然后选择概率最高的那一张呈现给那位特定的用户。
效果检测
离线检测
前文提到,Contextual bandits算法框架实际上是一种在线的机器学习法。在给用户推荐完海报后,我们会使用离线检测技术去检测它的效果,这种技术被称之为“Replay技术”。这种方法可以让我们对算法无偏差地进行离线衡量(如下图所示)。换句话说,我们可以通过这种离线衡量法,直观地看到如果在过去特定的场合中我们使用另一种算法会是什么结果。
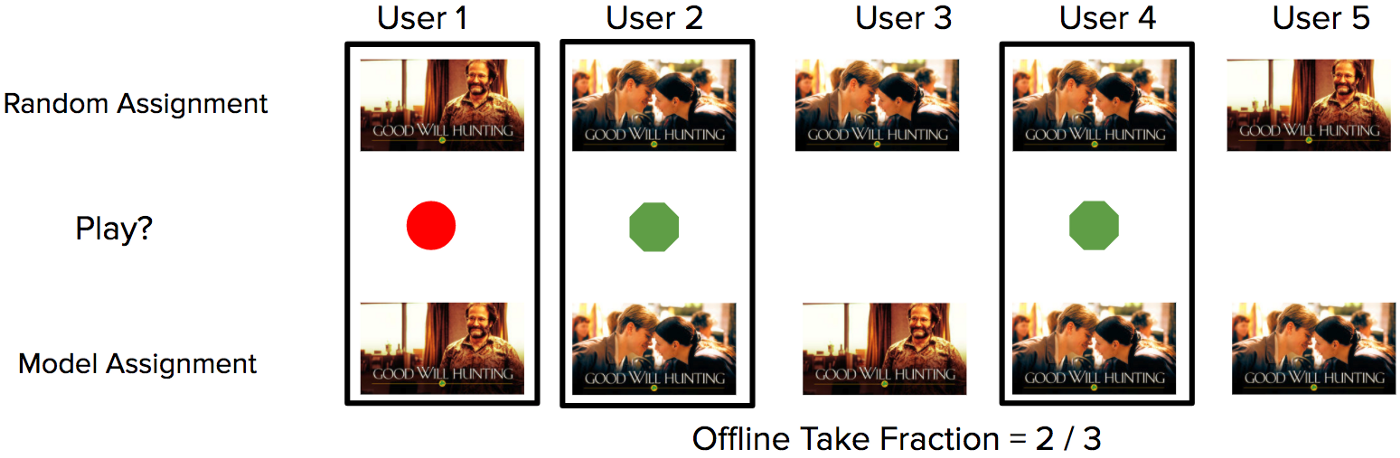
图片来自Medium
这是离线检测的一个简单案例:我们为每一位用户分配一张初始海报(横排第一行)。系统记录了这五位用户是否播放了这部剧,播放了则标绿,没有播放则标红(横排第二行)。离线检测则计算出新算法的推荐结果,并在这张图表里用黑色框圈出推荐算法和新算法结果相一致的结果(即用户1、用户2和用户4),然后计算这个集合中用户的点击率,也就是2/3。
Replay技术可以让我们直观地看到,如果我们推给用户的图片是根据新的算法,那么用户会如何反馈(即是否会观看这部剧)。
如前文所言,我们的目的在于通过展示合适的图片最大程度地吸引用户观看视频。下图显示了Contextual bandits算法如何帮只我们提高用户的点击率。
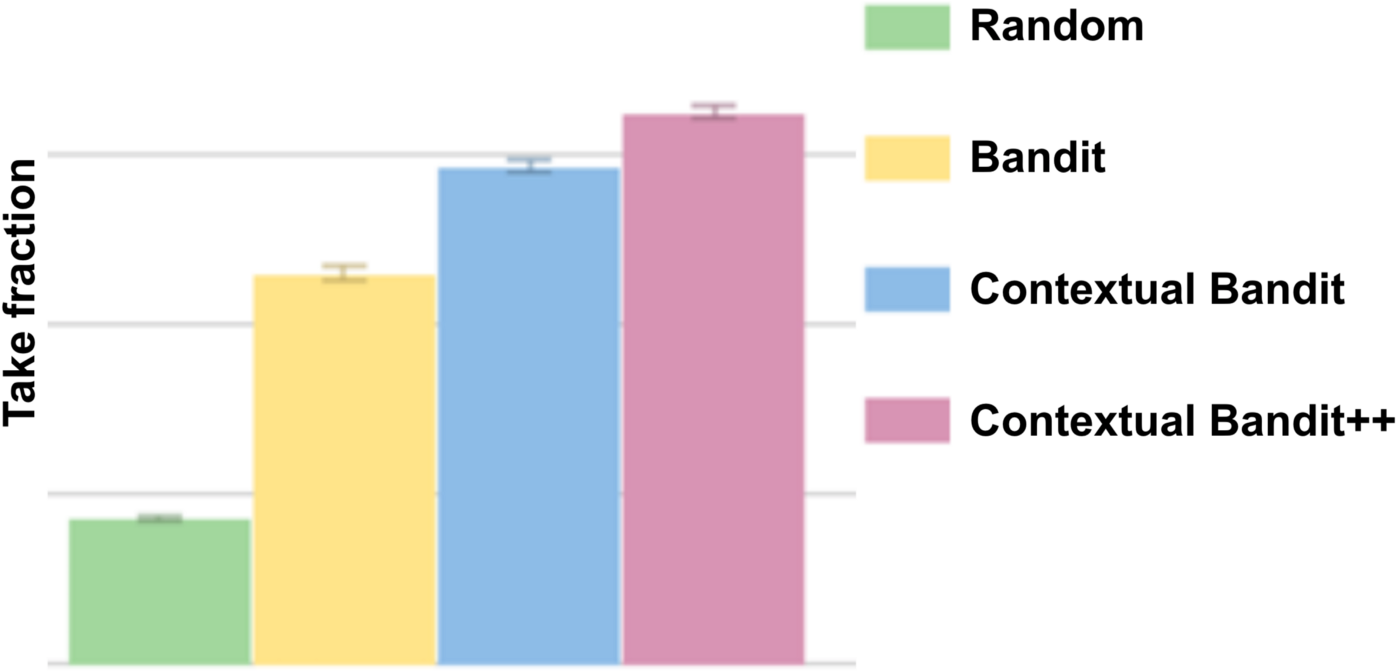
这张统计图显示了不同算法下观众的播放剧集的比例。其中蓝色和粉色为Contextual Bandit算法框架下的观众播放比例,可以看到它最大程度地吸引了观众点击剧集|图片来自Medium

这个例子展示了我们如何对海报进行打分。第一张海报的“喜剧值”为5.7;“浪漫值”为7.2。第二张海报的“喜剧值”为6.3;“浪漫值”为6.5。对喜欢浪漫故事的用户来说我们会倾向于为他推荐第一张海报;对喜欢喜剧故事的人来说我们会推荐第二张|图片来自Medium
在线检测
通过离线检测,我们检测出了效果最佳但是并没有被采用的算法,对后者而言,我们会再进行一次在线A/BTest,观察它在contextual bandits算法框架中的实际表现,根据结果及时调整算法。
正如我们期待的那样,这种测试大大提升了我们的核心指标,即用户对剧集的点击率。
同时,线上检测也让我们观察到了一些有趣的结果,比如对不了解某部剧的用户来说,这种点击率的提升是非常显著的。这也很容易理解:毕竟在不了解一部剧的前提下,个性化推荐才可能发挥更大的作用。
结论
通过前面介绍的Contextual bandits算法框架,我们实现了个性化推荐的第一步:为用户提供更吸引他们的剧集和海报。在这里,我们不仅解决了“推荐什么”的问题,更是解决了“如何推荐”的问题。这一步的意义是巨大的,因为我们可以为用户推荐符合他们口味的内容,以及用最吸引他们的方式介绍新的剧集。
当然,这仅仅是个性化推荐的一次尝试,我们的个性化推荐系统还有很多可以完善的地方,比如我们以后可以设计出新的算法,帮助我们快速准确地实现新剧集、新图像的冷启动处理,或者让用户体验的其他方面更加个性化,包括添加个性化的图片、引用文字和界面等等。
在个性化推荐的道路上,这仅仅是一个起点。
译者:Michiko









